分布式优化理论
随着网络科学的兴起及各类工程网络系统在社会中扮演越来越重要的角色,网络系统的优化与控制得到了广泛的研究关注。相较于依赖中心节点的传统优化算法,在无中心节点且数据分布于网络节点限制下完成网络系统最优决策的分布式优化算法因其所具有的可扩展性,数据分布性,网络鲁棒性、个体自主性、网络适应性等特点得到了越来越多的研究关注,并且分布式优化算法在通信网络、智能电网、大数据、智能楼宇、无人机等领域获得了广泛的应用。
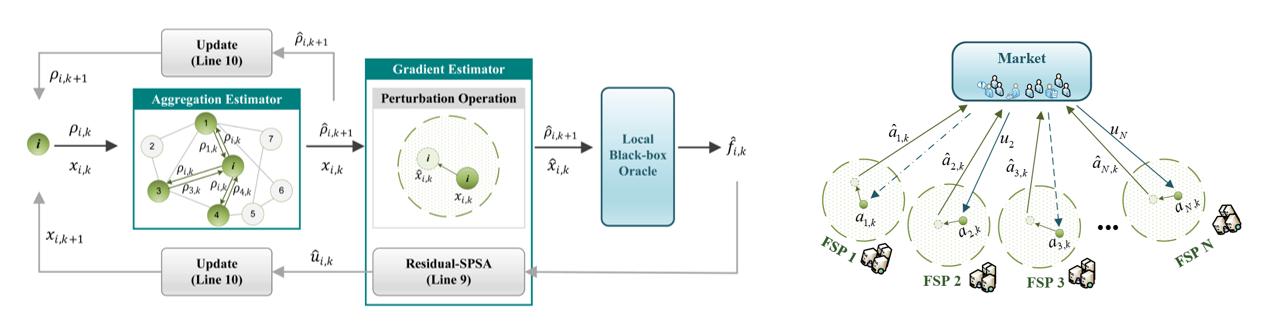
本实验室在相关分布式优化理论研究领域有着深厚的基础和国内领先水平,发表了多篇AUTO/TAC/CDC等领域顶会顶刊,具体研究内容包括但不限于对不同场景适应问题下的分布式优化算法的收敛性、收敛速度等的理论分析与数学推导,欢迎数学基础较好和感兴趣的同学加入相关研究课题:
1、 黎曼流形下的分布式优化及其加速算法分析:深入研究黎曼流形的几何特性,包括黎曼度量、联络、曲率等,理解其对优化过程的影响。将实际优化问题映射到黎曼流形上,设计基于黎曼流形的分布式优化算法,通过局部通信和信息交换实现全局优化。
2、 随机自适应的分布式优化算法分析与应用:
聚焦于研究如何在不确定性和动态变化的环境中,通过随机采样和自适应调整策略来优化分布式系统的性能。分析算法在不同随机噪声和动态场景下的收敛性、稳定性和鲁棒性,并将其应用于实际问题,如无线传感器网络中的能量优化等。
3、 多智能体分布式优化及其在智能电网的应用:在多智能体分布式优化及其在智能电网的应用方面,开展多智能体系统在智能电网中的协同优化研究。分析智能电网中各智能体(如分布式能源、储能设备、负荷等)之间的交互关系和优化目标,设计分布式优化算法实现智能电网的能量管理和调度。
相关成果论文:
Lei J, Shanbhag U V. Variance-reduced accelerated first-order methods: Central limit theorems and confidence statements[J]. Mathematics of Operations Research, 2025, 50(2): 1364-1397.
Yang Y, Lei J. Analysis of coupled distributed stochastic approximation for misspecified optimization[J]. Neurocomputing, 2025, 622: 129310.
Huang S, Lei J, Hong Y, et al. No-regret distributed learning in subnetwork zero-sum games[J]. IEEE Transactions on Automatic Control, 2024.
Zhao J, Yi P. A Robust Distributed Nash Equilibrium Seeking Algorithm for Aggregative Games Under Byzantine Attacks[C]//2024 American Control Conference (ACC). IEEE, 2024: 863-868.
Li C, Guo G, Yi P, et al. Distributed pose-graph optimization with multi-level partitioning for multi-robot SLAM[J]. IEEE Robotics and Automation Letters, 2024.
Lei J, Yi P, Chen J, et al. Distributed variable sample-size stochastic optimization with fixed step-sizes[J]. IEEE Transactions on Automatic Control, 2022, 67(10): 5630-5637.
Lei J, Shanbhag U V. Distributed variable sample-size gradient-response and best-response schemes for stochastic Nash equilibrium problems[J]. SIAM Journal on Optimization, 2022, 32(2): 573-603.
Lei J, Shanbhag U V. Stochastic Nash equilibrium problems: Models, analysis, and algorithms[J]. IEEE Control Systems Magazine, 2022, 42(4): 103-124.
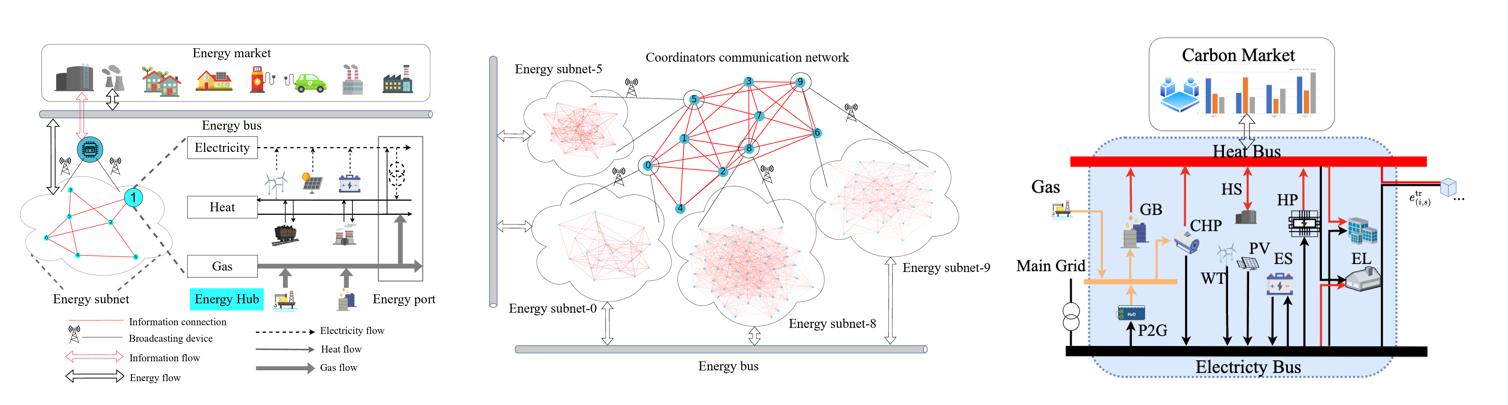
非合作博弈的均衡计算
非合作博弈是博弈论中的一个重要分支,研究在没有合作的情况下,个体如何通过理性决策选择策略以最大化自身利益。其核心概念是纳什均衡,即每个玩家在其他玩家策略不变的情况下无法通过改变自己的策略获得更好结果。均衡的计算方法包括最佳回应法、线性规划、动态规划等,但由于大规模博弈中参与者众多,计算复杂度较高。非合作博弈的均衡概念广泛应用于市场竞争、拍卖设计等领域。课题组在非合作博弈的均衡计算领域有着深厚的基础,发表了AUTO/TCNS/TNSE和CDC/ACC等顶刊、顶会成果:
1、非合作博弈广义纳什均衡的分布式计算以及在线学习:针对随机聚合博弈中智能体仅可使用邻居信息和带噪声的梯度信息的场景,结合镜像梯度法与动态平均跟踪设计了新型的分布式学习算法,实现动态重复博弈的次线性无悔均衡策略学习,并给出了变分遗憾界定量分析。针对具有损失bandit反馈的非合作博弈纳什均衡求解问题,提出了异步在线学习策略,自适应调整下一步行动以最小化长期遗憾损失。针对管理集成可再生能源发电、能源转换和能源交易的能源互联网系统,提出了一个网络化的 Stackelberg 博弈框架, 使得公司在做出决策时会考虑与其他公司的战略互动,同时考虑被动消费者在点对点约束条件下的最佳反应,结果证明了系统的运营效率和战略稳定性,强调了积极参与市场对能源公司和消费者的优势。
2、聚合博弈问题的分布式决策方法:在很多应用场景中,每个智能体的收益除了受到自己策略的影响,还受到全部参与者决策的总和(聚合量)的影响,此时聚合结构可以很好的建模这些智能体之间的策略耦合关系。为了应对同时具有竞争和合作两种特征的多智能体聚合博弈决策问题,提出了多簇聚合博弈的数学模型。多簇聚合博弈以每个簇为非合作博弈的参与者,簇间呈现了竞争的关系,而簇内的智能体之间呈现合作的关系。针对该模型提出了一种结合网络共识估计以及梯度下降方法的分布式纳什均衡求解算法,并证明其指数收敛速率。针对最小信息环境下的分布式聚合博弈纳什均衡计算问题,提出了一种基于残差bandit反馈的分布式在线梯度下降算法,揭示了算法遗憾界限、网络连接和博弈结构之间的关键关联,且当博弈严格单调时,该无悔算法生成的动作序列几乎必然收敛到纳什均衡。
相关成果论文:
Chen Y, Yi P, Lei J, et al. A Stackelberg Game Framework for Energy Internet System By Operator Approach[J]. IEEE Transactions on Network Science and Engineering, 2025.
Liu W, Lei J, Yi P, et al. No-regret learning for repeated non-cooperative games with lossy bandits[J]. Automatica, 2024, 160: 111455.
Chen Y, Yi P. Distributed Stackelberg Equilibrium Seeking for Networked Multi-Leader Multi-Follower Games with A Clustered Information Structure[J]. IEEE Transactions on Control of Network Systems, 2024.
Liu W, Yi P. Distributed No-regret Learning in Aggregative Games with Residual Bandit Feedback[J]. IEEE Transactions on Control of Network Systems, 2024.
Wang T, Yi P, Chen J. Distributed mirror descent method with operator extrapolation for stochastic aggregative games[J]. Automatica, 2024, 159: 111356.
Yi P, Lei J, Chen J, et al. Distributed linear equations over random networks[J]. IEEE Transactions on Automatic Control, 2022, 68(4): 2607-2614.
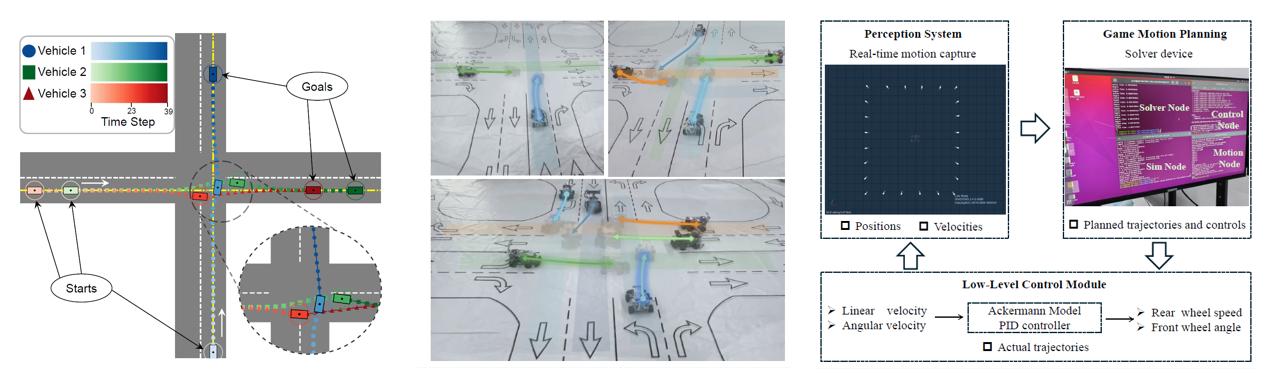
自动驾驶博弈轨迹规划
自动驾驶技术的快速发展正在重塑未来交通的格局。在自动驾驶系统中,驾驶决策本质上是多智能体之间资源竞争的博弈行为。与传统的决策方式不同,博弈论为多智能体的交互建模提供了一个坚实的理论基础。通过求解博弈中的均衡状态,我们能够为每个智能体生成最优的轨迹规划,实现对复杂交通场景的精准预测和协同决策。这种方法不仅能够捕捉到各参与者的动态行为,还能有效应对交互带来的不确定性,为自动驾驶系统在复杂环境中的智能决策提供理论支持和技术保障。
该研究方向聚焦于利用博弈论进行轨迹规划,推动自动驾驶系统在复杂交互场景下的智能决策与优化。通过构建多智能体博弈模型,我们能够同时为不同交通参与者生成规划与预测轨迹,从而实现安全、高效的交通管理。该研究不仅关注理论创新,更致力于解决实际应用中的关键问题,如安全性、鲁棒性和实时性等,为自动驾驶技术的进一步发展提供理论支撑和实践指导。
在这个充满挑战与机遇的时代,博弈论轨迹规划研究方向正在成为推动自动驾驶技术进步的核心驱动力。我们期待通过持续创新,为自动驾驶系统的智能化发展贡献力量,同时为智能交通系统的构建开辟新的可能性。
相关成果论文:
Liu Z, Lei J, Yi P, et al. An interaction-fair semi-decentralized trajectory planner for connected and autonomous vehicles[J]. Autonomous Intelligent Systems, 2025, 5(1): 1-20.
Pan Y, Lei J, Yi P, et al. Towards Cooperative Driving among Heterogeneous CAVs: A Safe Multi-Agent Reinforcement Learning Approach[J]. IEEE Transactions on Intelligent Vehicles, 2024.
Wang W, Yi P, Hong Y. Multi-Vehicle Trajectory Planning at V2I-enabled Intersections based on Correlated Equilibrium[J]. IEEE Robotics and Automation Letters, 2024.
Yi P, Wang W, Liu Q, et al. Motion planning at intersections with safe differential games based on control barrier function[C]//2024 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2024: 2049-2054.
多智能体对抗博弈
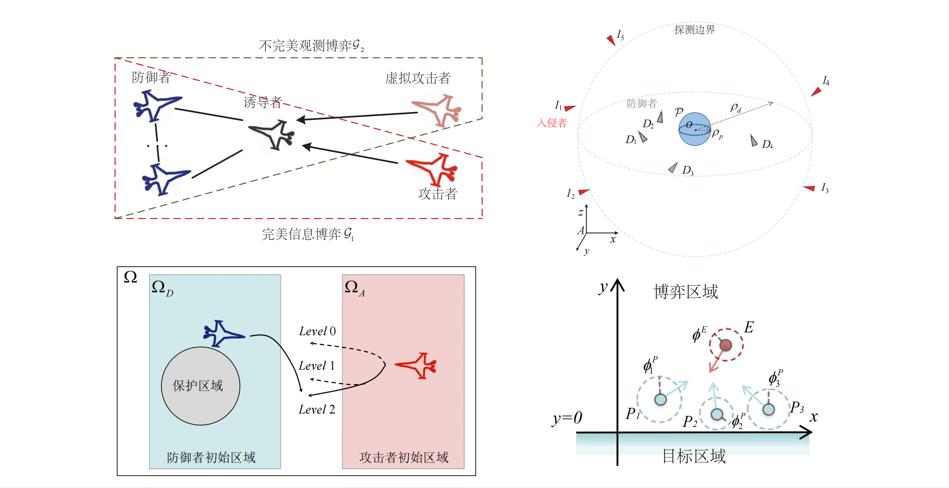
多智能体对抗博弈是人工智能前沿的核心研究方向。它描述多个具备自主决策能力的智能体在目标冲突环境下,通过动态策略交互实现自身效用最大化的过程。这种博弈具有零和性、策略竞争性和动态博弈性的特点。在这种环境中,各智能体既是策略的竞争者,也是时变场景中的适应者,需要不断地权衡自身收益与对手变化之间的关系。多智能体对抗博弈依托博弈论与控制理论,包括纳什均衡、微分对策以及多人零和博弈等,为策略设计提供数学工具。这一过程具有动态竞争决策(实时响应环境与对手行为)、资源争夺导向(通过竞争获取路权或战略位置)及纳什均衡驱动三大核心特征,广泛存在于智能交通博弈变道、棋类AI对决、自主网络攻防和军事演训等场景等场景。
一方面,课题组针对这一问题,在不确定信息的背景下,从观测不确定性、对手模型不确定性和对手决策模式不确定性三个维度出发,进行离散时间动态博弈和微分博弈数学建模,并设计相应的鲁棒估计方法与博弈数值求解方法。
另一方面,课题组聚焦于多智能体对抗博弈的理论建模、算法设计与应用实践,致力于解决多智能体系统在强对抗场景下的策略优化与决策协同问题。研究内容涵盖不完全信息下的集群追逃博弈、异构集群多任务对抗博弈和带误解欺骗策略库的对抗博弈等核心方向,分别针对不同场景设计了适应性马尔可夫决策模型、策略生成框架与协同博弈算法。未来,研究将进一步聚焦强对抗博弈中的异构智能体协同进化问题,推动多智能体博弈算法在智能交通、无人机编队、网络攻防和军事演训等领域的应用落地,为构建更智能、鲁棒的对抗决策系统提供理论与技术支撑。
相关成果论文:
Wang X, Yi P, Hong Y. A Hierarchical Deep Reinforcement Learning Strategy for Collective Pursuit-Evasion Game with Partial Observations[J]. IEEE Transactions on Artificial Intelligence, 2025.
Fang H, Yi P. Game-theoretic planning for multiplayer defense task with online objective function parameter estimation[J]. ISA transactions, 2025, 157: 318-328.
Fang H, Yi P. Adaptive Decision-Making in Attack-Defense Games With Bayesian Inference of Rationality Level[J]. IEEE Transactions on Industrial Electronics, 2024.
Fang H, Chen Y, Yi P. Cooperative Path Planning for Multiplayer Reach‐Avoid Games under Imperfect Observation Information[J]. Advanced Intelligent Systems, 2024, 6(9): 2300794.
多智能体强化学习
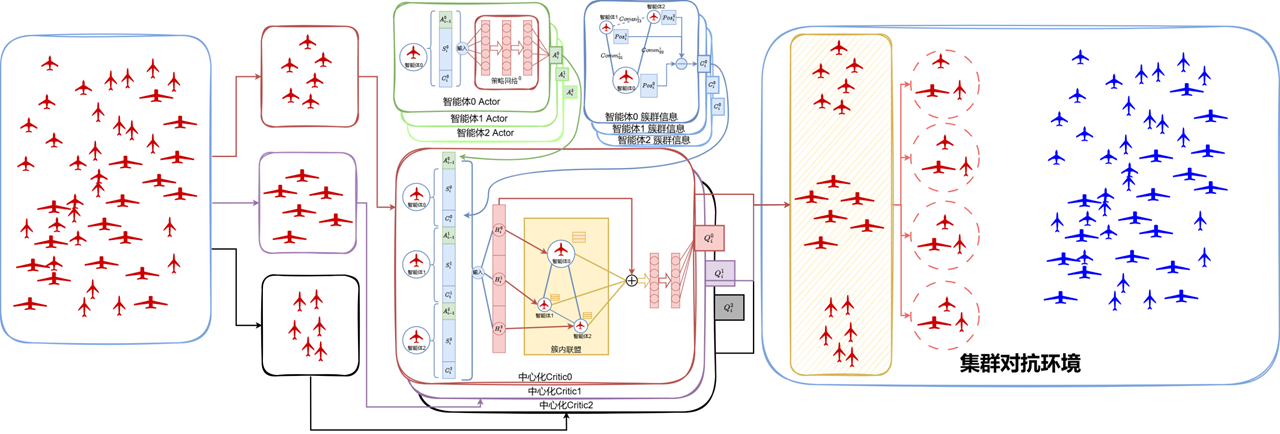
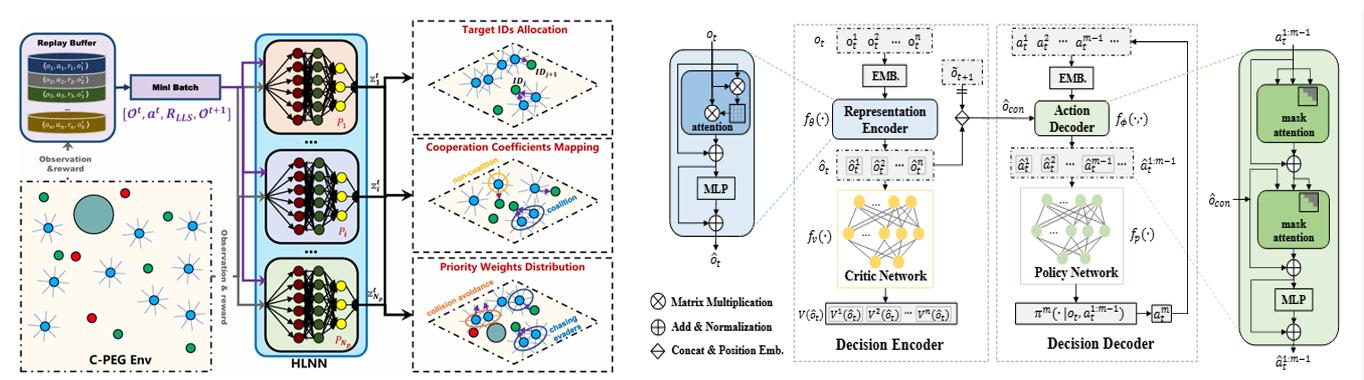
多智能体强化学习(MARL)是人工智能研究的重要分支,聚焦于多个智能体在共享或对抗环境中通过交互学习实现最优决策策略。在复杂场景下,多个智能体需协调合作、博弈对抗或自主决策,面临着环境非平稳性、策略依赖性、部分可观测等一系列挑战。MARL技术已广泛应用于智能交通控制、机器人集群协作、对抗博弈与智能制造等关键领域。
课题组围绕多智能体系统中的协同学习与高效决策等关键问题,提出了一系列具有创新性的MARL算法与框架。主要研究包括:
1、研究图上MARL方法,提升机器人集群任务分配与追捕规避博弈中的协作与效率;
2、针对大规模智能体通信与协调问题,研究基于MARL的通信学习机制以及高效联合策略模型;
3、研究样本高效的MARL方法,提升复杂合作-对抗环境下的学习效率与适应能力。
相关成果论文:
Lv Y, Lei J, Yi P. A Local Information Aggregation-Based Multiagent Reinforcement Learning for Robot Swarm Dynamic Task Allocation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025.
Wang X, Yi P, Hong Y. A Hierarchical Deep Reinforcement Learning Strategy for Collective Pursuit-Evasion Game with Partial Observations[J]. IEEE Transactions on Artificial Intelligence, 2025.
Pan Y, Lei J, Yi P, et al. Towards Cooperative Driving among Heterogeneous CAVs: A Safe Multi-Agent Reinforcement Learning Approach[J]. IEEE Transactions on Intelligent Vehicles, 2024.
Lv Y, Lei J, Yi P. Graph-Based Deep Reinforcement Learning Approach for Alliance Formation Game based Robot Swarm Task Assignment[C]//2024 IEEE 63rd Conference on Decision and Control (CDC). IEEE, 2024: 5079-5085.
Pan Y, Lei J, Yi P. Heterogeneous Multi-Agent Reinforcement Learning based on Adaptive Curiosity for Traffic Signal Control[C]//2024 American Control Conference (ACC). IEEE, 2024: 239-244.
Wei D, Yi P, Lei J. Multi-agent deep reinforcement learning for large-scale platoon coordination with partial information at hubs[C]//2023 62nd IEEE Conference on Decision and Control (CDC). IEEE, 2023: 6242-6248.
大语言模型智能体
大语言模型智能体的蓬勃发展正在革新人工智能的应用范式。在复杂任务执行场景中,任务处理本质上是多智能体之间能力协同的动态过程。与传统的任务执行方式不同,多智能体协同理论为智能体之间的交互与协作提供了科学框架。通过分析智能体间的分工与协作关系,能够为每个智能体制定最优执行策略,实现对复杂任务的高效拆解和协同完成。这种方式不仅可以精准把握各智能体的优势与特点,还能灵活应对任务过程中的突发变化,为大语言模型智能体在实际业务场景中的落地应用提供理论支撑与实践路径。
课题组聚焦于:1、解决强化学习在智能体协调中奖励函数设计的难题;2、研究大语言模型驱动的对抗性任务策略生成方法;3、研究基于大语言模型的飞行器轨迹生成方法。